.png)

Data annotation might sound technical, but it’s a cornerstone of artificial intelligence (AI) and machine learning (ML). Without it, AI models can’t learn or improve.
Think of it as teaching a machine to differentiate between a mushroom and a piece of pepperoni on a pizza: annotation is an integral step in the process that makes it possible.
At Viam, we take a practical approach to data annotation, building tools that simplify the process and empower developers to create smarter systems. In this blog, we’ll break down the basics of data annotation, why it’s essential, the challenges it presents, and how Viam helps users tackle them.
What is data annotation?
Data annotation is the process of labeling or tagging raw data to provide context. If you’ve ever searched your phone for a photo of a specific location or a friend’s face, you’ve seen annotations in action. For instance, metadata like time, location, or objects in an image help your phone sort and find photos.

In ML, annotation is more structured. It involves tools like bounding boxes, which outline objects in an image, or labels that categorize data. These annotations allow machines to recognize and classify patterns, objects, or behaviors.
As one Viam engineer explained, “Annotations are like telling the model the truth—it learns what we teach it.”
Why is data annotation essential?
Annotations serve two critical purposes in ML:
- Organization: Annotations help group data into meaningful datasets. For example, if you’re collecting sensor data across several experiments, some may include faulty readings due to hardware malfunctions. Annotations can exclude these noisy datasets and highlight high-quality data.
- Training: Annotations act as the foundation for model training. For example, labels on an image can teach a model to identify specific objects, like distinguishing between a mushroom and a piece of pepperoni on a pizza.

This dual role—organizing and training—makes data annotation a non-negotiable step in ML workflows.
Types of data annotation
At Viam, our platform supports three primary types of data annotation:
Image annotation
This includes tools for object detection and classification.
- Object detection: This process involves identifying and locating multiple objects within an image. By drawing bounding boxes around each object, the model learns not only what the objects are but also where they are situated within the image. For instance, in a street scene, object detection can identify and locate cars, pedestrians, and traffic lights, providing precise coordinates for each.

- Image classification: This task assigns a label to an entire image based on its predominant content. Unlike object detection, image classification doesn't specify object locations but determines the main subject of the image. For example, an image classification model might analyze a picture and classify it as containing a dog or a cat, without indicating their positions within the image.

For example, you can use bounding boxes to outline objects in an image, helping ML models learn to distinguish between them.
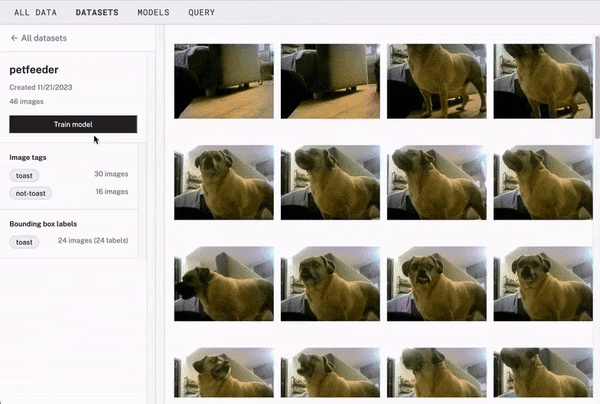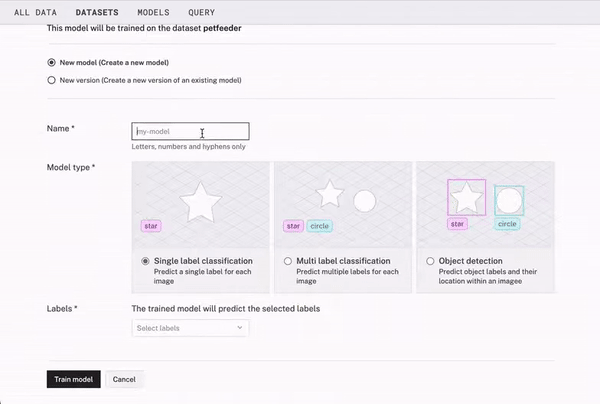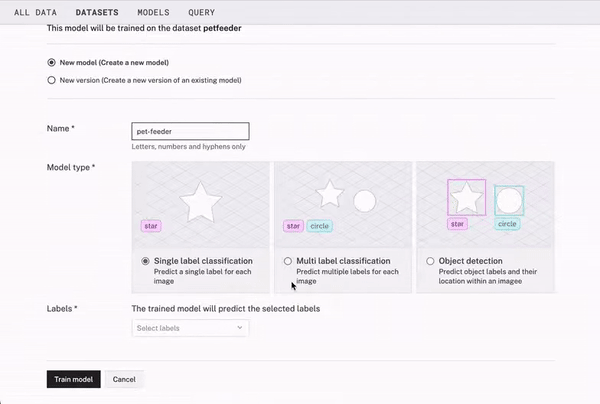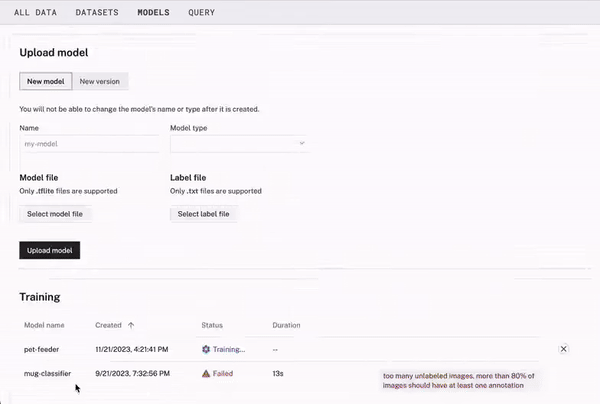
Video annotation
Viam enables video annotation by allowing developers to apply the same data annotation techniques used for static images to videos. This supports tasks like tracking objects across frames or annotating recurring patterns.
Video annotation is particularly valuable for applications such as traffic monitoring, object detection in dynamic environments, and more. By correlating objects between frames, Viam provides tools for training models that can recognize continuity and movement.
For example, our Principal Solutions Engineer created an object detection model to identify whether workers on a construction site were following safety protocols by wearing helmets. By annotating video footage frame by frame, the model was trained to detect instances of compliance or non-compliance, ensuring workplace safety and regulatory adherence.
Sensor data annotation
This is particularly relevant for IoT and smart machine applications. Viam’s tools allow developers to annotate physical environment data, such as temperature readings or object localization.
While these are our focus today, Viam’s modular platform is adaptable, making it possible to extend annotation support to other areas in the future.
How data annotation supports machine learning
Improving training workflows
Annotations make ML training more efficient and accurate. High-quality annotations ensure models are learning from clean and reliable datasets, reducing errors during deployment.
Take a common example from Viam: in the food processing industry, engineers annotate pizza images with bounding boxes to identify toppings. These annotations feed into models that optimize sorting processes, reducing time and waste.

Addressing noisy data
Another common use case is managing faulty sensor data. Say an experiment outputs inaccurate temperature readings due to sensor issues. Annotations can flag these readings, which can later be filtered out, ensuring they don’t disrupt model training.
The challenges of data annotation
Time-intensive workflows
Let’s face it—data annotation can be a time-intensive process. Manually labeling thousands of images or datasets demands significant effort, and for teams on tight deadlines, it can quickly become overwhelming. Viam streamlines this process with:
- User-friendly tools: Intuitive interfaces for drawing annotations, such as labeling an image with a bounding box directly within the Viam app.

- Auto-labeling: Viam supports workflows that integrate Vision Language Models (VLMs) and grounding models as part of a “two-phase” process. For example, a grounding model like Grounding Dino can detect objects (e.g., a person), while a VLM refines these detections by confirming attributes (e.g., whether the person is wearing glasses). If both models agree, the system can automatically annotate the image and add it to the dataset.

Scaling annotations across datasets
As your dataset grows, managing annotations becomes exponentially harder. Without the right tools, you risk creating bottlenecks that slow your entire workflow. Enter Viam:
- Integrated platform: Annotate, train, and deploy—all in one seamless ecosystem. No need to jump between tools, and no extra complexity to manage.
- Effortless scalability: Whether you’re working with a small dataset or scaling to thousands of data points, Viam’s tools grow with your needs.
By addressing these common challenges, Viam takes the guesswork—and the hassle—out of data annotation, so you can focus on building smarter, better-performing models.
Best practices for effective data annotation
The better your data annotations are, the better your model performs. But how do you make sure your annotations are actually working for you? Here are some ways to build a workflow that’s consistent, efficient, and accurate:
- Set clear guidelines: Consistency is everything in data annotation. For example, determine whether to annotate only primary objects of interest (like helmets on workers) or include secondary objects (like gloves or safety vests). Having clear rules minimizes confusion and keeps your annotations uniform across the dataset.
- Leverage automation: Leverage automation: Why spend hours on manual labeling when advanced tools can provide a head start? As mentioned above, by using advanced VLMs, you can automate this process. These models can perform visual inferences, assisting in the annotation of specific models.
- Conduct quality checks: Regularly review your annotations to catch any errors or inconsistencies. It’s easy for a misaligned bounding box or mismatched label to derail your model’s accuracy, so don’t skip this step!
- Diversify your dataset: Make sure your data reflects a wide range of conditions—think lighting, angles, and environments. The more varied your dataset, the better your model will perform in real-world applications.
- Include negative examples: Sometimes, teaching your model what isn’t important is just as valuable. For instance, if you’re building an object detection model for construction site safety, include images of workers both with and without helmets to avoid false positives.
- Balance your data: No one likes a biased model. Make sure each class in your dataset has equal representation. This ensures your model doesn’t favor one category over another.
Build a data annotation pipeline
Viam makes it easy to create and manage annotations for training ML models. Whether you're working with images, video frames, or sensor data, our intuitive platform streamlines the process from start to finish.
Step 1 - Prepare your dataset
Start by collecting diverse, high-quality data. Use Viam’s tools to upload images, videos, or sensor data and ensure your dataset reflects real-world conditions.

Step 2 - Annotate your data
Label your dataset using Viam’s annotation tools, such as bounding boxes or classification tags. Consistency and diversity in your labels are key to ensuring robust model performance.

Step 3 - Train your model
Train your ML model directly on Viam’s platform by selecting your dataset, defining the task type (e.g., image classification or object detection), and starting the training process.
Step 4 - Deploy and refine
Deploy your model in minutes and monitor its real-world performance. Continue refining your dataset and annotations as new data becomes available.

For detailed instructions on annotating data, visit our image classification guide and our object detection guide.
Why Viam stands out for data annotation
Viam’s platform is designed to support your data annotation journey, whether you’re labeling images, video frames, or sensor data. Here’s how:
- Ease of use: Viam’s tools are designed for efficiency, allowing users to annotate quickly and accurately.
- Integrated ecosystem: Annotate, train, and deploy—all within the same platform. This end-to-end approach eliminates the need for external tools and ensures consistency.
- Real-world applications: From diagnosing machine faults to improving food processing workflows, Viam’s tools address practical challenges faced by engineers and developers.
Take, for example, a customer in the food processing industry who used Viam’s platform to automate the annotation of food images. This saved time and streamlined their workflow, from labeling to deployment.

From raw data to smarter systems
High-quality data annotation doesn’t have to be a headache. With the right practices and tools, you can create robust datasets that drive smarter machine learning models.
At Viam, we’re committed to making this process as seamless and efficient as possible. With intuitive tools and an integrated ecosystem, we empower developers to focus on innovation rather than logistics.
Get started with data annotation today
Ready to get started? Explore Viam ML to see how our platform can transform your AI workflows, and head to our documentation to annotate your machines’ data today.
Technical reviewers: Tahiya Salam (Lead Engineer, ML Team) and Vignesh Pandiarajan (New Grad, Data Rotation)