You may not be familiar with the term "object detection," but you’ve most likely come into contact with it in one way or another. This field of computer vision is quietly working behind the scenes in your everyday life.
Think about how easy it is to unlock your phone with just your face or scan your fruit at a self-checkout in the grocery store—these conveniences are made possible by object detection.
With object detection, you can visibly see where designated objects are within an image.
But what exactly is object detection, and how does it work?
In this guide, I’ll walk you through the basics of object detection, how it’s used in everyday life, the technology that makes it possible, and what you’ll need to know before diving in yourself.
Whether you're curious about how things work or are someone who wants to see how this technology can be useful in your projects or business, this blog is for you.
What is object detection within computer vision?
Object detection is essentially what it sounds like: a process that involves analyzing an image or video of a scene to detect specific objects within it. It’s focused on answering the questions, “What objects are in this image?" and "Where are they located?"
The designated objects of flowers and people being detected by an object detection model. Built with Viam’s ML Model Service.
If you're looking for people, for example, the technology will scan the scene, draw boxes around all the detected individuals, label them as "person," and provide a confidence score indicating how certain it is that each detected object is actually a person.
This allows you to identify and analyze specific objects within a scene accurately and efficiently.
Object detection is a way of identifying where specific objects are within an image or video. Built with Viam’s ML Model Service.
To put it another way, imagine viewing the world through the lens of a camera. The camera captures everything in its view, but object detection steps in to identify and highlight key objects within the image.
This allows you to quickly and accurately focus on what matters most, creating a clearer image.
Want to bring this project to a classroom or club? Explore Viam for Educators for resources to help teach the workshop.
While object detection and image classification are both considered tasks of computer vision, they have distinct differences. You might think of object detection as a more advanced version of image classification.
Image classification is a way of identifying what objects are within a single image or video. Built with Viam’s ML Model Service.
Image classification, also referred to as object recognition, operates on the assumption that there is a single object or class to be identified in an entire image. For example, an image classification model might look at a picture and determine that it belongs to the class "dog," or "cat," or "fish," without specifying where within the image the object is located.
To learn more about image classification, head to our guide.
This image shows the difference between object detection and image classification.
In contrast, object detection not only identifies multiple objects within an image but also determines their exact coordinates. For example, in an image of a living room, object detection can simultaneously identify and locate dogs, cats, and fish, drawing bounding boxes around each one.
This multi-object capability builds on the foundation of image classification by adding spatial information.
Object detection vs. image segmentation
Image segmentation takes things a step further than object detection by performing pixel-level classification. Instead of just identifying and locating objects, image segmentation classifies each pixel in the image, outlining the precise shape of every object.
This image shows the difference between object detection and image segmentation.
So, while image classification provides a general label for an entire image, object detection adds the ability to pinpoint where multiple objects are within the scene, and image segmentation offers even finer detail by classifying every pixel.
Each of these tasks plays a crucial role in the broader field of computer vision, enabling machines to interpret and interact with the visual world in increasingly sophisticated ways.
What are the different approaches to object detection in computer vision?
The field of object detection has seen significant change over the past decade. In 2011, the deep learning algorithm DanNet outperformed traditional methods by a factor of three, sparking a widespread shift toward this approach.
Since then, object detection has been split into what we call traditional object detection (pre-2011) and deep learning object detection (post-2011).
Traditional object detection
Traditional object detection methods rely on handcrafted features and heuristic algorithms, making educated guesses about pixel patterns based on predefined criteria. Heuristics, which are rules of thumb or strategies derived from experience, are used in these models to identify simple shapes, detect shading differences, and find contours and colors.
For example, to detect a tomato, you might scan the image for areas where the red component (R) in the RGB color model exceeds a certain threshold. Anything sufficiently red would be flagged as a potential tomato.
An apple being wrongly identified as a tomato due to the heuristics traditional object detection models within computer vision relied on.
Similarly, one of the first facial detection models used on a digital camera, the Fujifilm FinePix S6500fd, relied on an algorithm that identified facial features like eyes and nose shadows based on light and dark patterns.
An image showing how a facial detection model looks from a camera’s viewpoint.
Popular traditional algorithms for object detection
Some of the popular traditional object detection techniques include:
Scale-Invariant Feature Transforms (SIFT) - 1999: Detects and describes local features in images, making it robust to changes in scale, rotation, and lighting.
Viola-Jones Detector - 2001: Primarily used for face detection, this algorithm employs a series of simple feature classifiers to rapidly and accurately detect faces in images.
Showing Haar-like features, which are instrumental in the Viola-Jones algorithm, allowing cameras to detect certain patterns that suggest facial regions.
Histogram of Oriented Gradients (HOG) - 2005: Used for detecting objects, like pedestrians, by counting occurrences of gradient orientation in localized portions of an image.
While groundbreaking at the time, these methods were inflexible and hard to use for general-purpose detection tasks, such as identifying multiple different kinds of objects at once.
This made the rise of deep learning-based object detection around 2014 all the more important, as it brought greater flexibility and accuracy by learning features directly from data.
Deep learning object detection
Deep learning object detection models use neural network layers, like convolutional neural networks (CNNs), which scan images layer by layer, mimicking the brain's pattern recognition processes. CNNs further refine object detection by progressively learning features, starting from fine details and moving to larger patterns.
A diagram showing how convolutional neural networks (CNNs) operate, similarly to the primary visual cortex of the brain. (source)
Imagine a viewfinder moving across an image, detecting changes from light to dark and learning shapes that define specific objects, like fur patterns or scales.
Through iterative training, the network starts by recognizing fine details and progressively builds up to understanding the entire image.
For instance, you might show a neural network many images of rooms containing tomatoes, apples, and people wearing red shirts. Over time, the network learns to distinguish between the pixels of a tomato and those of an apple, developing a "certainty" of what constitutes a tomato.
How does object detection work?
Before we explore the various object detection frameworks, it’s important to note that while these frameworks are valuable, they’re not essential for creating an object detection model. So, don’t be discouraged if you’re not familiar with them.
With that, let’s dive in!
Types of deep learning object detection model architectures
Object detection can be achieved through various model architectures, that can be broadly categorized into single-stage and two-stage detectors. Both types of detectors use CNNs to analyze images and pinpoint objects.
Let’s examine the details of each architecture type.
A list of popular one and two stage object detection algorithms.
Single-stage detectors and algorithms
Single-stage detectors perform object detection in a single pass through the network, making them faster and more efficient.
Diagram showing how single-stage detectors perform object detection in a single pass through the network.
These models predict both the bounding boxes and the class probabilities directly from the full images in one go, without needing a separate region proposal stage.
This makes them particularly suitable for real-time applications where speed is crucial.
YOLO (You Only Look Once) family
YOLO models are a prime example of single-stage detectors, known for their ability to detect objects in a single pass through the network.
Imagine a city struggling with traffic congestion, aiming to reduce gridlock, spot potential accidents, and enhance overall safety. While various object detection models could be used, YOLO models are particularly effective due to their fast-processing speeds, allowing traffic officers to detect and classify objects in real-time.
This capability can significantly improve the traffic management system by enabling dynamic adjustments to traffic light timings, immediate dispatch of emergency services, and real-time information sharing with commuters.
A look at how YOLO object detection models work in a single pass through the network.
Iterative improvements on the original YOLO have led to versions like YOLOv2, YOLOv3, YOLOv4, and YOLOv5, each enhancing performance and accuracy. While the most recent version is YOLOv10, YOLOv8 is widely considered the most stable at the moment, as it’s been tested extensively.
To learn more about YOLO models, check out our guide.
CenterNet
CenterNet identifies objects by detecting their centers and associated attributes. This method simplifies the detection process and improves speed by focusing on the central points of objects rather than scanning the entire image for edges and shapes.
A look at how CenterNet algorithm works for object detection.
Two-stage detectors and algorithms
Two-stage detectors, on the other hand, involve a more complex process where object detection is broken down into two stages.
The first stage involves generating region proposals, which are candidate regions within an image that might contain objects.
The second stage involves classifying these proposals and refining their boundaries to improve detection accuracy.
A diagram showing how two-stage detectors work, passing images and videos through multiple stages to detect objects. (source)
This two-step approach, while generally slower than single-stage detectors, tends to provide higher accuracy, especially for more challenging detection tasks.
R-CNN family
R-CNN (2014): The original R-CNN (Region-based Convolutional Neural Network) was the first notable algorithm of its kind to use a two-stage object detection framework. First, it defines region proposals, and then classifies these regions independently.
While it was transformative for its ability to detect multiple objects within an image, it was relatively slow due to its two-step process and high computational power.
A diagram showing R-CNN’s process.
Fast R-CNN (2015): To improve on the lagging ways of the R-CNN algorithm, the creator, Ross Girshick, created Fast R-CNN. This model processes the entire image in a single forward pass, using a region of interest (RoI) pooling layer to extract features from each proposed region, significantly speeding up detection.
A diagram showing Fast R-CNN.
Faster R-CNN (2015): Introducing a region proposal network (RPN), Faster R-CNN further optimizes the process by generating region proposals in real-time. This end-to-end training approach enhances both speed and accuracy.
A diagram showing Faster R-CNN.
Mask R-CNN: Building on Faster R-CNN, Mask R-CNN adds a branch for predicting segmentation masks on each RoI, enabling instance segmentation. This allows for more detailed object recognition and separation within an image.
Cascade R-CNN: Cascade R-CNN addresses issues of overfitting and quality mismatch by training a sequence of detectors with increasing IoU (Intersection over Union) thresholds. This cascade structure improves detection accuracy and robustness.
And, keep in mind that with Viam, you can build your own object detection model in under an hour.
How do you train an accurate object detection model?
As mentioned earlier, building your own object detection model doesn't have to be complicated. In fact, you don't even need to code to get started!
For deep learning object detection, Viam’s ML Model Service handles all the heavy lifting for you. All you need is time and patience to complete what’s sometimes considered a tedious task.
Providing an enriched dataset
Compiling data for your dataset
The first step in training data is having data to train. With Viam’s Data Management Service, you can gather data from any camera, whether it's your phone, computer, or other models, directly to the Viam app.
Additionally, if you already have data you’re looking to train, you can upload it to Viam’s app in minutes. Head to our documentation on uploading a batch of data to learn more.
An image of the config tab within Viam's app, showing data capture as on.
My top tips for pulling in the best training data
Remember, "Garbage in, garbage out"—if your training data lacks variation, your model will too.
Here are some rules to remember as you’re compiling data:
More data means better models: Incorporate more data from varying environments, such as lighting conditions or distances, to improve your model’s overall performance.
Include counterexamples: Your data should include both the target object and other objects to improve accuracy. It’s also important to provide images with and without what you’re looking to detect.
Avoid class imbalance: Don’t train excessively on one specific type or class. For instance, if you're training a dog detector, include images of various dog breeds to avoid bias towards one breed, such as a Dalmatian.
Provide consistency between your training and testing data: Make sure the conditions and contents of your testing data closely match your training data. Imagine you’re looking to create an object detection model to detect apples and oranges at any time of the day, but you only feed it pictures during daylight hours. This would alter the conditions of the images, reducing the accuracy of the object detection model.
Labeling and training your data
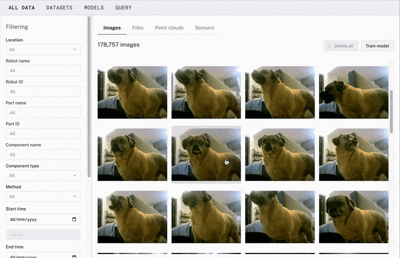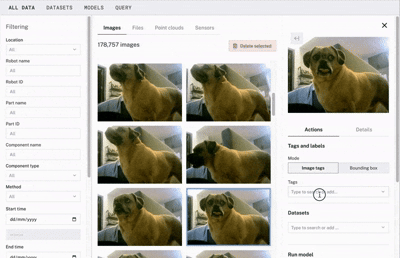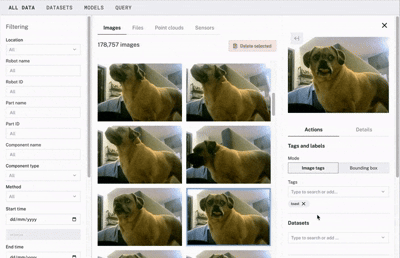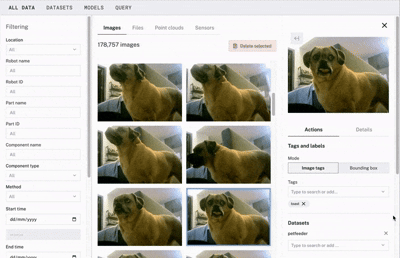
Once your data is enriched with diverse environments, conditions, and object appearances, it’s time to label it. That’s where bounding boxes come into play.
What is a bounding box?
Bounding boxes are rectangular borders used in object detection to highlight and specify the location of objects within an image. They’re key to many computer vision tasks, as they provide a clear and standardized way to represent the position and size of objects.
These boxes are typically defined by the coordinates of their top-left and bottom-right corners in a 2D space, where x represents the horizontal axis and y represents the vertical axis.
Showing the training process of an object detection model in Viam. As you can see the image is being tagged with a bounding box and then labeled as “dog.”
Creating bounding boxes for object detection
With Viam, you can easily create bounding boxes directly within the app to label and train your data. For example, if you want to train your smart pet feeder to dispense specific treats for each of your dogs while also making sure it doesn’t mistakenly feed your friends' pets, here’s what you would do:
Draw bounding boxes around your dogs in each of your images.
Add or select the label that corresponds to their name (e.g., “Sophie,” “Chip”).
Showing the training process within Viam, this time with a close-up view.
When training new models in the Viam app, we use fine-tuning, a transfer learning approach. This means you only need to label about a hundred images instead of hundreds or thousands, making the process significantly faster and more resource-efficient.
After labeling your images, you can train your model with Viam in just a few minutes by following the detailed instructions in our documentation.
My top tips for labeling and training your data
If you’re training your first model or have struggled with training in the past, follow these tips for high-quality data preparation:
Label data correctly: Accurate labeling is essential. Use bounding boxes to precisely highlight and specify the location of the objects.
Label images with and without the object: Ensure your dataset contains images both with and without the target object to improve the model's accuracy.
Label a sufficient amount of images: While at least 10 images are a minimum requirement, we recommend having significantly more to achieve more accurate results. Just think, the more images you label with or without the object, the more precise it will be.
Deploying your object detection model to any device
The last step is to deploy and test your model on your machine, whether it be an IoT device, home automation system, or robotic system. This can be done in as little as 5 minutes, using Viam’s built-in configuration.
Showing the deployment process of a ML model in Viam.
Using pre-trained object detection models with Viam
If you’re looking to save time and deploy a model from another repository, like HuggingFace, Model Zoo, or Kaggle, to your machine, this is totally doable with Viam. You have a few options, including:
Deploying a pre-trained model another community member has published on the Viam Registry. If you have one in mind, I’d look here first as it’s the easiest way to deploy it onto your own machine.
Uploading a model to the Viam Registry yourself, making it private or public so others can use it on their devices later.
Deploying a model that’s trained outside the Viam platform that’s already available on your machine.
Just make sure the model you use is compatible with the Viam platform, which supports TensorFlow Lite, TensorFlow, PyTorch, and ONNX model frameworks.
Testing the accuracy of your object detection model
Once you've deployed your object detection model to your machine, you'll want to check that it's accurately identifying the objects you've specified.
Within the Viam app, you can test if your model is working accurately.
If your model isn't performing reliably after deployment, you might need to make some adjustments. You can try:
Adding and labeling more images in your dataset if you trained the model yourself. This can boost accuracy.
Lowering the confidence threshold of the transform camera. Ideally, your ML model should identify objects with high confidence, which usually depends on having a robust dataset.
Now that you know how to train and deploy an accurate object detection model, let's explore its practical uses.
What are the applications of object detection?
Remember how I mentioned that object detection is all around us? Object detection plays a crucial role in various fields—from the workplace to travel and so much more—leveraging the sense of sight to automate and enhance tasks that rely on visual recognition.
Avoiding obstacles when moving, recognizing people for security purposes, and detecting defects in manufacturing are all cases where object detection is in play.
Quality assurance
Credit computer vision for ensuring your products arrive just as you expected. By identifying defects on production lines—such as color inconsistencies, dents, or scratches—object detection helps companies maintain high product quality and reduces the risk of faulty products reaching the market.
Safety compliance
You might not realize it, but object detection is also making workplaces safer by keeping an eye on compliance with safety protocols. Imagine you're a construction worker where wearing hardhats and gloves is mandatory.
With object detection, companies can detect whether employees are wearing their helmets and automatically alert the safety officer if someone isn't. This way, everyone stays safe and sticks to the necessary precautions.
A dataset trained on Viam, showing a YOLOv8 Hard Hat Detection model, in use at a construction site.
Plant care
Object detection extends its benefits to hobbies and daily activities, including indoor gardening. It can monitor your plants, detecting issues like browning leaves or pests.
By automating responses such as watering or spraying insecticides, it helps keep your plants healthy with minimal effort, potentially saving your beloved fiddle leaf fig from wilting.
Pet care
Pet care also benefits from object detection, allowing owners to automate and monitor many aspects of their animals’ day-to-day activities.
It can detect when pets approach their food bowls and automatically dispense food, ensuring they are fed on time. Additionally, it can monitor pets' movements to make sure they get enough exercise, or recognize individual pets in multi-pet households, providing personalized care and attention.
An object detection model being trained directly on Viam for logic that automatically gives the dog, Toast, a treat whenever he’s spotted.
Face and person recognition
Object detection is widely used in facial recognition systems, helping to identify individuals for security and access control purposes.
For retail, it could look at customer behavior and count the number of people in a store, providing valuable data for optimizing store layouts and staffing levels.
Traffic flow management
Object detection is increasingly used in traffic flow management. By automating the analysis of live traffic data through machine learning models, it optimizes traffic signals and flow, leading to better road construction and maintenance decisions. This real-time analysis helps manage traffic congestion and improves safety for both pedestrians and drivers.
The object detection model showing how it could be used with traffic flow management.
Autonomous vehicles
Self-driving cars rely heavily on object detection to identify and navigate around pedestrians, vehicles, and obstacles, ensuring safe and efficient operation. With it, these vehicles can interpret their surroundings accurately, making real-time decisions to avoid collisions and navigate complex environments.
An object detection model within the Viam app interface, showing how people and cars can be identified to help autonomous vehicles navigate safely.
Get started with object detection today
Object detection is an integral part of modern computer vision, and its applications span various fields, from ensuring product quality to enhancing safety and even caring for pets and plants.
Ready to build your first object detection model? It’s easily done using Viam’s ML Model Service—all without needing to write a single line of code.
Jump in, experiment with different models, and let Viam handle the heavy lifting, so you can bring your vision to life with minimal effort. To get started with an object detection project, try one of the projects found in our blog, DIY home automation projects for 2024 featuring Raspberry Pi.
About the author: Khari is a computer vision enthusiast interested in democratizing access to robotics and technology. His work focuses on multiple object tracking, image detection, and other machine learning applications of computer vision.
Reviewed by: Bijan Haney (Lead Engineer, CV Team at Viam) and Nick Hehr (Senior Developer Advocate at Viam)
Find us at our next event
May 6, 2025
–
May 6, 2025
,
07:00-09:00 PM EST
Elastic New York Meetup
In Person
New York, NY
Monitor and automate the physical world with Elastic and Viam. Join us for a demonstration of gathering data from a fleet of sensors, visualizing it with Kibana, and creating alerting rules that trigger in real life.
Interested in robotics, but don't know where to start? Meet Viam in Miami, where Adrienne Tacke will discuss how to get up and running, even if you're "just" a software developer.
Curious how startups are using Viam to build smart, vision-enabled products, even on low-power hardware? Join Viam engineers for a live computer vision demo and Q&A.
WebRTC is most often associated with building video and text chat into browsers but this peer-to-peer technology can also be used to monitor and control machines from anywhere in the world! Join Nick Hehr to learn about industrial arms, DIY rovers, and dashboards of data in real time.
Edge-based computer vision gives us real-time insights, but getting that data where it needs to go without high bandwidth, lag, or hardware strain is a big challenge. Learn how to build a fast, event-driven vision pipeline.